Backpropagation-Algorithmus
Das Backpropagtion-Verfahren wurde 1986 von Rumelhart, Hinton und Williams in ihrem berühmten Artikel Learning representations by back-propagating errors angegeben und hat wesentlich dazu beigetragen, dass der damalige so genannte KI-Winter beendet wurde und dem Verfahren des maschinellen Lernens erneut große Aufmerksamkeit gewidmet wurde.
Vorbemerkung
In diese Unterkapitel geht es recht technischer zu. Daher ist dieses Unterkapitel nicht so sehr zum Selbstlernen für Schüler:innen geeignet, sondern richten sich eher an Lehrer:innen zum Verständnis des mathematischen Hintergrunds.Grundsätzliche Idee der Backpropagation
Wie im vorhergehenden Kapitel betrachten wir weiterhin die Kostenfunktion $C_x(w,b)$, welche für eine feste Eingangsgröße $x$ ein Maß dafür angibt, wie stark die Ausgangsaktivierungen $a^L(x)$ von den gewünschten Ergebnissen $y(x)$ abweichen. Die Kostenfunktion $C_x(w,b)$ ist eine Funktion, die von sämtlichen Gewichten $w = (w_{jk}^l)_{j,k,l}$ und Biases $b=(b_j)_j$ des KNN abhängt:
\begin{eqnarray} C_x(w,b) := {1 \over 2} \| y(x) - a^L(x)\|^2 = {1 \over 2} \sum_k ( y(x) - a^L(x) )^2 \nonumber \end{eqnarray}Es soll nun ein Verfahren angegeben werden, bei dem in jedem Lernschritt für einen festen Eingangswert $x$ alle Gewichte $w$ und Biases $b$ gleichzeitig neu justiert werden.
Mit $z^l:= w^l a^{l-1} + b^l$ bezeichnen wir die Propagierungsfunktion des $l$-ten Layers. Beachte, dass hierbei $w^l$ Matrizen und dass $a^{l-1}$ und $z^l$ Vektoren sind. Die Aktivierungsfunktion des $l$-ten Layers lautet damit also:
\begin{eqnarray} a^l = \sigma (z^l) = \sigma (w^l a^{l-1} + b^l) \nonumber \end{eqnarray}Beachte, dass dabei die Anwendung von $\sigma$ auf den Vektor $z^l$ komponentenweise gemeint ist. Das heißt, in Koordinatenschreibweise ergibt sich für die Aktivierungsfunktion:
\begin{eqnarray} a_j^l = \sigma (z_j^l) = \sigma (\sum_k w_{jk}^l a_k^{l-1} + b_j^l) \nonumber \end{eqnarray}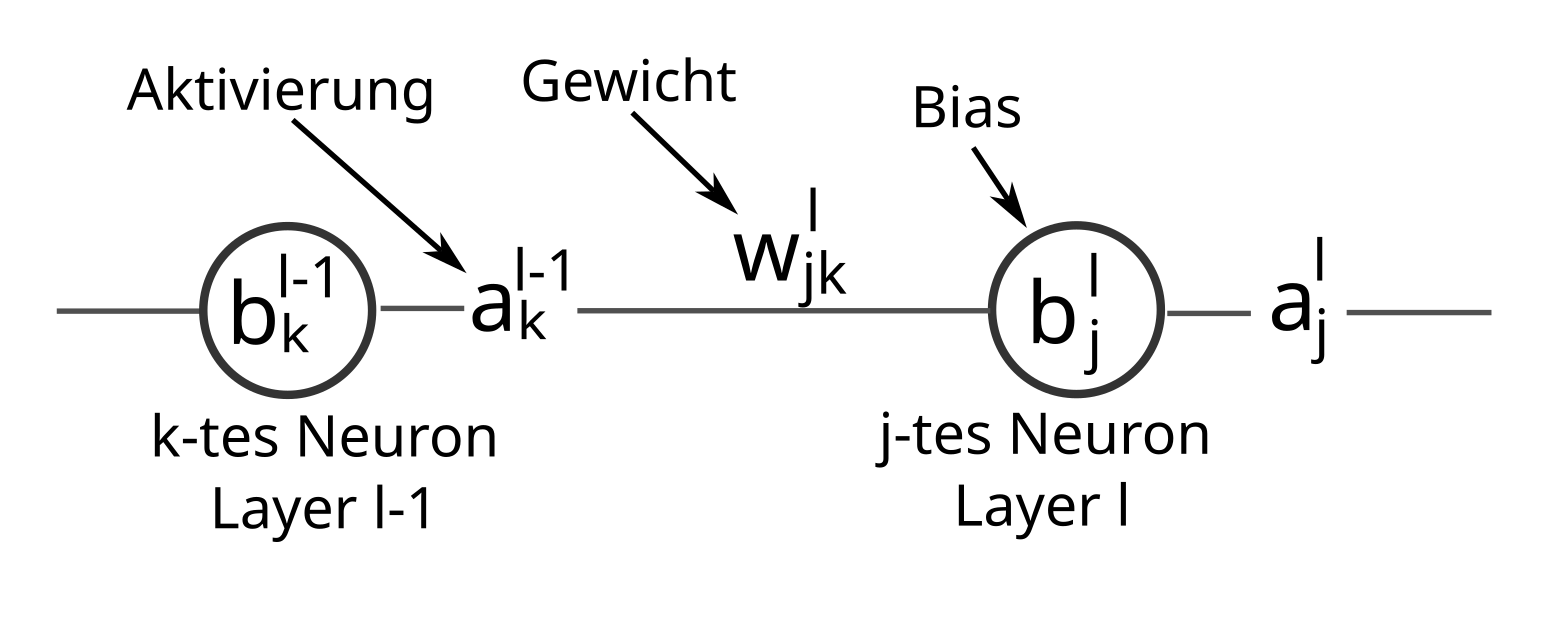
Die grundlegende Idee der Backpropagation besteht darin, zunächst die Fehler $\delta^L$ des Ausgabelayers (also die Abweichungen der Ausgangsaktivierungen $a^L(x)$ von den gewünschten Aktivierungen $y(x)$) zu betrachten. Genauer definieren wir den Fehler im $l$-ten Layer als:
\begin{eqnarray} \delta^l := {\partial C_x \over \partial z^l} := ({\partial C_x \over \partial z_j^l})_j \nonumber \end{eqnarray}Da der Fehler $\delta^L$ ja von den Gewichten $w^L$ und Biases $b^L$ abhängt, ist die Idee nun, in jeder Iteration diese Gewichte und Biaes so neu zu justieren, dass der Fehler $\delta^L$ etwas kleiner wird (Gradientenabstiegsverfahren).
Weiterhin muss ja der Fehler $\delta^L$ durch einen Fehler $\delta^{L-1}$ im vorhergehenden Layer zustande gekommen sein. Daher wird in jedem Iterationsschritt auch berechnet, wie groß dieser Fehler $\delta^ {L-1}$ gewesen sein muss.
Dieses Vorgehen wird nun für das gesamte KNN durchgeführt. Das heißt, ausgehend vom Fehler $\delta^l$ des Layers $l$ werden die Gewichte $w^l$ und Biases $b^l$ durch Gradientenabstieg angepasst. Anschließend wird der Fehler $\delta^{l-1}$ im vorhergehenden Layer $l-1$ berechnet. Dieses Vorgehen wird solange wiederholt, bis man beim Eingangslayer angekommen ist.
Da man dabei vom Ausgabelayer startend iterativ rückwärts durch das gesamte KNN bis zum Eingabelayer läuft, wird dieses Vorgehen als Backpropagation der Fehler bezeichnet. In einem Backpropagationschritt werden dabei alle Gewichte $w = (w_{jk}^l)_{j,k,l}$ und alle Biases $b=(b_j)_j$ des KNN gleichzeitig so justiert, dass der Ausgabefehler insgesamt im Sinne der Kostenfunktion etwas kleiner wird.
Nun zu der genaueren mathematischen Ausarbeitung der Backpropagation:
Mathematische Herleitung der nötigen Formeln
Berechnung des Fehler $\delta^L$ des Ausgabelayers
Wegen $a_j^L = \sigma(z_j^L)$ und der Kettenregel gilt: \begin{eqnarray} \delta_j^L = {\partial C_x \over \partial z_j^L} = {\partial C_x \over \partial a_j^L} \sigma^\prime (z_j^L) \nonumber \end{eqnarray} Weiter folgt wegen $ C_x(w,\Theta) = {1 \over 2} \sum_k ( y_k(x) - a_k^L(x) )^2$: \begin{eqnarray} {\partial C_x \over \partial a_j^L} = (y_j-a_j^L)\cdot(-1)=a_j^L-y_j \nonumber \end{eqnarray} Damit ergibt sich für den Fehler $\delta^L$ also insgesamt: \begin{eqnarray} \delta_j^L = (a_j^L - y_j) \cdot \sigma^\prime (z_j^L) \nonumber \end{eqnarray} Wird nun noch mit $\circ$ das Hardamard-Produkt notiert, so ergibt sich in Vektorschreibweise: \begin{eqnarray} \boxed{\delta^L = (a^L - y) \circ \sigma^\prime (z^L)} \label{eq:BP1} \end{eqnarray} Mit Hilfe dieser Formel lässt sich also der Fehler $\delta^L$ nach erfolgter Forwardpropagation sofort berechnen.Anmerkung
Wegen $(\nabla_{a^L} C_x)_j = ({\partial C_x \over \partial a_j^L})_j = (a_j^L - y_j^L)_j$ sich der Fehler $\delta^L$ in Gradientenschreibweise auch notieren als: \begin{eqnarray} \delta^L = \nabla_{a^L} C_{x} \circ \sigma^\prime (z^L) \nonumber \end{eqnarray}
Backpropagation des Fehlers vom Layer $l+1$ zum Layer $l$
Der Fehler $\delta^{l+1}$ in einem nachfolgenden Layer muss ja durch einen Fehler $\delta^l$ in dem vorhergehenden Layer zustande gekommen sein. Deshalb ist unser Ziel nun, eine Formel für den Fehler $\delta^{l} = \delta^{l} (\delta^{l+1}$) als Funktion des Fehlers $\delta^{l+1}$ des nachfolgenden Layers herzuleiten. Mit Hilfe dieser Formel kann dann der Fehler $\delta^{l+1}$ iterativ rückwärts durch das gesamte KNN bis zum Eingangslayer propagiert werden. Man nennt dieses Vorgehen deshalb Backpropagation des Fehlers durch das gesamte KNN.
Dazu betrachten wir zunächst die Abhängigkeit der Propagierungsfunktion $z^{l+1}$ von der Propagierungsfunktion $z^{l} $ im vorhergehenden Layer. Wegen $a_j^l = \sigma(z_j^l)$ gilt zunächst: \begin{eqnarray} z_k^{l+1} = \sum_i w_{ki}^{l+1} a_i^l + b_k^{l+1} = \sum_i w_{ki}^{l+1} \sigma(z_i^l) + b_k^{l+1} \nonumber \end{eqnarray} Daraus folgt für die Abhängigkeit $z^{l+1}$ von $z^l$ sofort: \begin{eqnarray} {\partial z_k^{l+1} \over \partial z_j^{l}} = w_{kj}^{l+1} \sigma^\prime(z_j^l) \nonumber \end{eqnarray} Für den Fehler $\delta^l$ folgt daraus mit der Kettenregel: \begin{eqnarray} \delta_j^l &=& {\partial C_x \over \partial z_j^l} \nonumber \\ &=& \sum_k {\partial C_x \over \partial z_k^{l+1}} \cdot {\partial z_k^{l+1} \over \partial z_j^{l}} \nonumber \\ &=& \sum_k \delta_k^{l+1} \cdot {\partial z_k^{l+1} \over \partial z_j^{l}} \nonumber \\ &=& \sum_k \delta_k^{l+1} \cdot w_{kj}^{l+1} \sigma^\prime(z_j^l) \nonumber \\ &=& \sum_k w_{kj}^{l+1} \delta_k^{l+1} \sigma^\prime(z_j^l) \nonumber \end{eqnarray} In Matrixschreibweise kann diese Gleichung elegant geschrieben werden als: \begin{eqnarray} \boxed{\delta^l = (w^{l+1})^T \delta^{l+1} \circ \sigma^\prime(z^l)} \label{eq:BP2} \end{eqnarray} Mit Hilfe dieser Gleichung ist also unser Ziel erfüllt und wir können aufgrund der Kenntnis des Fehler $\delta^{l+1}$ jeweils den Fehler $\delta^l$ im vorhergehenden Layer $l$ berechnen (Backpropagation des Fehlers). Beachte dabei, dass die Werte $z^l$ aufgrund der vorangegangenen Forwardpropagation bereits alle bekannt sind.Korrektur der Biases $b$
Nachdem nun also durch Backpropagation sämtliche Fehler $\delta^l$ für alle Layer $l$ des KNN bekannt sind, können wir uns anschauen, wie die Biases so neu justiert werden können, dass die Kostenfunktion $C_x$ für den immer noch festen Eingangswert $x$ kleiner wird. Dazu betrachten wir die Abhängigkeit der Kostenfunktion von den Biases. Wegen $z_j^l = \sum_i w_{ji}a_i^{l-1} + b_j^l$ und der Kettenregel erhält man: \begin{eqnarray} {\partial C_x \over \partial b_j^l} &=& {\partial C_x \over \partial z_j^l} \cdot {\partial z_j^l \over \partial b_j^l} \nonumber \\ &=& \delta_j^l \cdot 1 \nonumber \end{eqnarray} In Vektorschreibweise also: \begin{eqnarray} \boxed{ {\partial C_x \over \partial b^l} = \delta^l } \label{eq:BP3} \end{eqnarray} Werden nach erfolgter Backpropagation sämtlicher Fehler $\delta^l$ durch das gesamte KNN also in jedem Layer die Bisaes $b^l$ nach der Vorschrift \begin{eqnarray} \Delta b^l := - \eta \delta^l \nonumber \end{eqnarray} angepasst, so wird die Kostenfunktion insgesamt kleiner. Das Netzwerk hat also also gelernt, den ursprünglichen Eingangswert $x$ im Sinne der Kostenfunktion besser zu verarbeiten. In der obigen Formel wurde noch eine Lernrate $\eta$ eingeführt, die verhindern soll, dass man zu schnell über lokale Minima der Kostenfunktion hinausläuft.Korrektur der Gewichte $w$
Analog zum Vorgehen bei den Biases leiten wir nun eine Formel für die Abhängigkeit der Kostenfunktion $C_x$ von den Gewichten $w$ her. Wiederum wegen $z_j^l = \sum_i w_{ji}a_i^{l-1} + b_j^l$ und der Kettenregel erhalten wir sofort: \begin{eqnarray} {\partial C_x \over \partial w_{jk}^l} &=& {\partial C_x \over \partial z_j^l} \cdot {\partial z_j^l \over \partial w_{jk}^l} \nonumber \\ &=& \delta_j^l \cdot a_k^{l-1} \nonumber \end{eqnarray} In Matrixschreibweise also: \begin{eqnarray} \boxed{ {\partial C_x \over \partial w^l} = \delta^l \cdot (a^{l-1})^T } \label{eq:BP4} \end{eqnarray} Analog zum Vorgehen bei den Biases werden auch die Gewichtswerte $w$ nach der folgenden Vorschrift neu justiert (Abstieg in Richtung des negativen Gradienten gedämpft um die Lernrate $\eta$): \begin{eqnarray} \Delta w^l := - \eta \delta^l \cdot (a^{l-1})^T \nonumber \end{eqnarray}Zusammenfassung der Update-Regeln
Backpropagation der Fehler $\delta^l$ durch das gesamte KNN und Gradient $\nabla_{\Theta,w} C_x$: \begin{equation} \boxed{ \begin{array}{rcl} \delta^L &=& (a^L - y) \circ \sigma^\prime (z^L) \\ \delta^l &=& (w^{l+1})^T \delta^{l+1} \circ \sigma^\prime(z^l) \\ {\partial C_x \over \partial b^l} &=& \delta^l \\ {\partial C_x \over \partial w^l} &=& \delta^l \cdot (a^{l-1})^T \end{array} \label{eq:BP} } \end{equation} Update der neuen Biases $b^l$ und Gewichte $w^l$: \begin{equation} \boxed{ \begin{array}{rcl} \Delta b^l &:=& - \eta \delta^l \\ \Delta w^l &:=& - \eta \delta^l \cdot (a^{l-1})^T \end{array} \label{eq:update_b_w} } \end{equation}Trainingsbatches
In tatsächlichen Anwendungen wird der Updateschritt meist nicht für einen einzelnen Trainingswert $x \in X$ aus den Trainingsdaten $X$ ausgeführt. Stattdessen betrachtet man eine ganze Teilmenge $B\in X$ und berechnet für jeden Wert $x \in B$ einen gemittelten Updateschritt: \begin{equation} \begin{array}{rcl} \Delta \Theta^l_{gesamt} &:=& {1 \over |B|} \sum_{x\in B} (- \eta \delta^l_x) \\ \Delta w^l_{gesamt} &:=& {1 \over |B|} \sum_{x\in B} (- \eta \delta^l_x \cdot (a^{l-1}_x)^T) \end{array} \label{eq:update_b_w_batchvariante} \end{equation} Das eigentliche Update der Gewichte und Biases wird also lediglich ein einziges mal für das komplette Trainingsbatch ausgeführt. Mit diesem Vorgehen soll erreicht werden, dass man erstens nicht so leicht über ein lokales Minimum der Kostenfunktion hinausläuft. Und zweitens soll auch vermieden werden, dass man in einem lokalen Minimum der Kostenfunktion steckenbleibt, falls nebenan eventuell noch weitere lokale Minima mit noch niedrigeren Kosten existieren. Die Trainingsbatches $B$ werden dabei jeweils nacheinander zufällig aus der Menge $X$ aller Trainingsdaten ausgewählt. Auch durch diese zufällige Wahl soll vermieden werden, über lokale Minima hinauszulaufen oder in lokalen Minima steckenzubleiben, welche global betrachtet noch nicht sonderlich gut sind.Lizenzangaben
Das vorliegende Unterkapitel orientiert sich an der Darstellung in dem online Buch von Michael Nielsen: Neural Networks and Deep Learning und unterliegt deshalb (anders als der Rest von inf-schule.de) der Lizenz „Creative Commons Attribution-NonCommercial 3.0 Unported License“. Die in diesem Unterkapitel neu ergänzten Bestandteile unterliegen zusätzlich der ShareAlike-Klausel.
