Spracherkennung mit der Brute-Force-Methode
Eine Grammatik für Gleitkommazahlen
Ziel ist es, die Spracherkennung über Ableitungen mit den Produktionen einer Grammatik zu automatisieren.
Wir vereinfachen zunächst die Darstellung der Produktionen:
| Grammatikregeln - in Langform | Grammatikregeln - in Kurzform |
|---|---|
floatnumber -> pointfloat floatnumber -> exponentfloat |
F -> P F -> E |
pointfloat -> fraction pointfloat -> intpart fraction pointfloat -> intpart "." |
P -> R P -> IR P -> I. |
exponentfloat -> intpart exponent exponentfloat -> pointfloat exponent |
E -> IX E -> PX |
intpart -> digit intpart -> digit intpart |
I -> D I -> DI |
fraction -> "." intpart |
R -> .I |
exponent -> "e" intpart exponent -> "E" intpart exponent -> "e" "+" intpart exponent -> "E" "+" intpart exponent -> "e" "-" intpart exponent -> "E" "-" intpart |
X -> eI X -> e+I X -> e-I |
digit -> "0" digit -> "1" digit -> "2" digit -> "3" digit -> "4" digit -> "5" digit -> "6" digit -> "7" digit -> "8" digit -> "9" |
D -> 0 D -> 1 D -> 2 D -> 3 D -> 4 D -> 5 D -> 6 D -> 7 D -> 8 D -> 9 |
Beachte, dass wir hier darauf verzichten, den Exponenten mit "E" darzustellen. Das liegt letztlich daran, weil dann Großbuchstaben als Nichtterminalsymbole gedeutet werden können.
Spracherkennung mit Hilfe von Produktionen
Spracherkennung mit Hilfe von Produktionen scheint ganz einfach zu sein. Man muss - ausgehend vom Startsymbol - lediglich die "richtigen" Produktionen anwenden. Schon hat man gezeigt, dass die betreffende Gleitkommazahl korrekt gebildet ist.
F -> # mit F->P P -> # mit P->I. I. -> # mit I->DI DI. -> # mit D->2 2I. -> # mit I->D 2D. -> # mit D->1 21.
Nur, woher weiß man, welche Produktion die richtige ist? Als Mensch hat man Überblick und kann die richtige Produktion auswählen. Ohne diese Übersicht muss man mit anderen Strategien an die Auswahl der anzuwendenen Produktionen gehen, z.B. so:
F ->
P ->
R ->
.I # keine Fortsetzung möglich
IR ->
DR ->
0R # keine Fortsetzung möglich
1R # keine Fortsetzung möglich
2R
2.I # keine Fortsetzung möglich
DIR ->
...
Aufgabe 1
(a) Welche Strategie wird hier benutzt, um eine Ableitung zum Wort 21. zu finden?
(b) Setze die Ableitungsversuche passend zur Strategie um einige Schritte weiter fort.
(c) Warum könnte man die benutzte Strategie als "Brute-Force-Strategie" bezeichnen?
Experimente mit JFlap
Mit Hilfe des Software-Werkzeugs JFlap kann man die Worterkennung mit Grammatiken experimentell testen.
Zunächst gibt man die Grammatik im Grammatik-Editor ein.
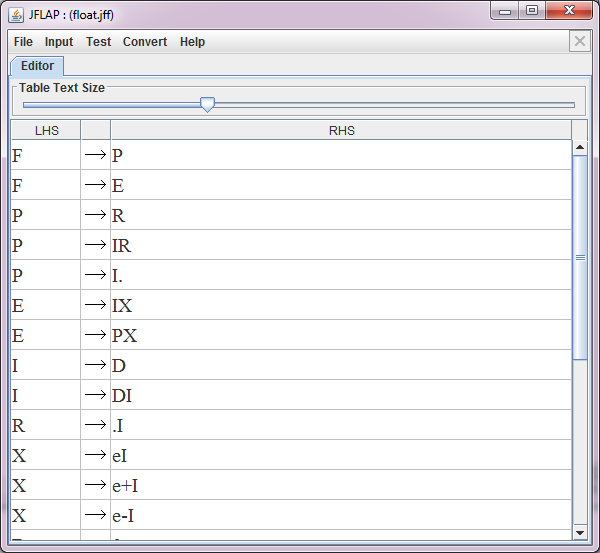
Zum Testen wählt man der Reihe nach die Menupunkte [Input] und [Brute Force Parse] aus.
In das [Input]-Feld gibt man die zu analysierende Zeichenfolge ein, z.B. 21..
Mit dem Menupunkt [Start] wird jetzt die Suche nach einer Ableitung zum eingegebenen Wortes mit Hilfe
der vorgegebenen Ersetzungsregeln gestartet. Achtung, diese Suche kann eine Weile dauern.
Wenn sie erfolgreich beendet wird, dann erhält man eine positive Rückmeldung und kann sich die
Ableitung anzeigen lassen.
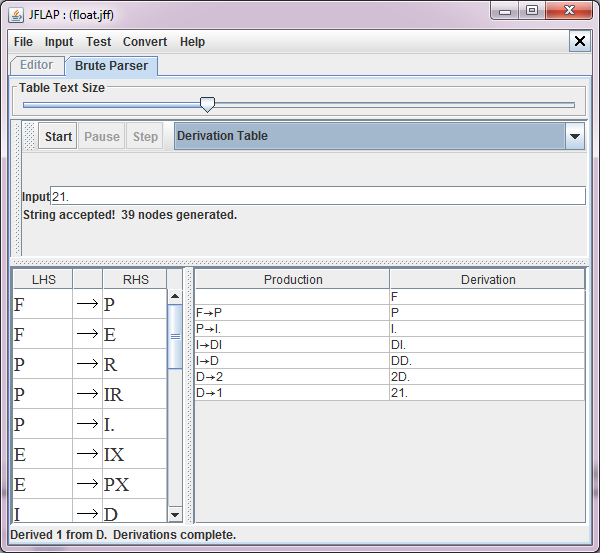
Aufgabe 2
(a) Probiere das selbst aus.
(b) Wie verhält sich JFlap, wenn die zu analysierenden Zeichenketten länger werden? Hast du eine Erklärung hierfür?
(c) Ist die Brute-Force-Methode eine praktikable Methode zur Spracherkennung bei Gleitkommazahlen? Woran liegt das?