Gradientenabstiegsverfahren
Datensatz
Wir betrachten wieder den bereits bekannten Datensatz mit den gefährlichen und ungefährlichen Tieren, für den nun ein künstliches Neuron entwickelt werden soll: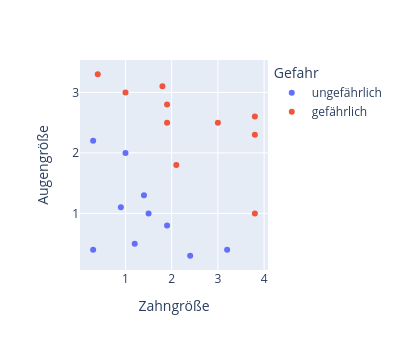
Statt die Gewichte und den Bias des künstliches Neurons per Hand zu justieren, sollen diese nun jedoch selbständig aus den Daten gelernt werden. Als Trainingsdatensatz verwenden wir die in der Abbildung dargestellten Daten.
Beachte, dass jedes Tier in diesem Datensatz durch einen Mensche gelabelt wurde, entweder als "ungefährliches" oder als "ungefährliches" Tier.
Progagierung und Aktivierung
Zunächst formulieren wir die Propagierungsfunktion z und die Aktivierungsfunktion a unseres künstlichen Neurons: \begin{eqnarray} z(x_1,x_2) &=& w_1 \cdot x_1 + w_2 \cdot x_2+b \\ a(z) &=& tanh(z) \end{eqnarray}Kostenfunktion
Um mit numerischen Daten arbeiten zu können, führen wir noch die so genannte Targetfunktion $t(x_1,x_2)$ eines Tieres ein: \begin{eqnarray} t(x_1,x_2) = \left\{\begin{array}{ll} +1 & \textrm{gefährlich} \\ -1 & \textrm{ungefährlich} \end{array}\right. \nonumber \end{eqnarray} MIt Hilfe dieser Targetfunktion definieren wir nun noch die so genannte Kostenfunktion $C_x$ eines einzelnen Datenpunktes $x$ als: $$ C_x = \frac{1}{2} (t_x-a_x)^2 $$ Mit dem Index $x$ soll hier angedeutet werden, dass die Kostenfunktion für ein einzelnes Tier $x$ formuliert wurde. Die Kostenfunktion $C_x$ wird also genau dann Null, wenn das künstliche Neuron an seinem Ausgang die korrekte Aktivierung a liefert.Beachte aber, dass die Kostenfunktion hierbei von den (momentan noch unbekannten) Gewichten und dem Bias abhängt, dass also gilt: $$ C_x=C_x(w_1,w_2,b) $$
Die Gesamtkostenfunktion $C_{ges}$ erhalten wir als Summe der einzelnen Kostenfunktionen: $$ C_{ges} = \sum_x C_x = \sum_x \frac{1}{2} (t_x-a_x)^2 $$ Unser Ziel wird im Folgenden sein, die Gewichte $w_1,w_2$ und den Bias $b$ des künstlichen Neurons so zu bestimmen, dass sich im Idealfall $C_{ges}=0$ ergibt, so dass dann also alle Tiere des Trainingsdatensatzes korrekt erkannt werden.
Beachte, dass es bei nicht separierbaren Daten nicht gelingen würde, die Kostenfunktion $C_{ges}$ komplett zum Verschwinden zu bringen. Trotzdem erkennt das künstliche Neuron viele Tiere (aber aber eben alle) korrekt, wenn es nur gelingt, den Wert der Kostenfunktion $C_{ges}$ möglichst klein zu machen.
Partielle Ableitungen
Wir betrachten nun die Kostenfunktion $ C_x=C_x(w_1,w_2,b) $ als Funktion der beiden Gewichte $w_1,w_2$ und des Bias b.Zunächst berechnen wir, wie sich $C_x$ mit Veränderung von $w_1$ ändert, wenn die beiden anderen Veränderlichen $w_2$ und $b$ konstant gehalten werden. Man spricht in diesem Fall von der so genannten partiellen Ableitung $\frac{\partial C}{\partial w_1}$ von $C_x$ nach $w_1$, die man durch mehrfache Anwendung der Kettenregel erhält als:
\begin{eqnarray} \frac{\partial C_x}{\partial w_1} &=& 2 \cdot \frac{1}{2} (t-a) \cdot (-1) \frac{\partial a}{\partial w_1} \\ &=& -(t-a) \left( 1-tanh^2(z) \right) \frac{\partial z}{\partial w_1} \\ &=& -(t-a) \left( 1-tanh^2(z) \right) \cdot x_1 \\ &=& -(t-a) \left( 1-a^2 \right) \cdot x_1 \end{eqnarray} Analog erhält man die anderen partiellen Ableitungen: \begin{eqnarray} \frac{\partial C_x}{\partial w_1} &=& -(t-a) \left( 1-a^2 \right) \cdot x_1 \\ \frac{\partial C_x}{\partial w_2} &=& -(t-a) \left( 1-a^2 \right) \cdot x_2 \\ \frac{\partial C_x}{\partial b } &=& -(t-a) \left( 1-a^2 \right) \end{eqnarray}Gradientenabstieg
Die partielle Ableitung $\frac{\partial C_x}{\partial w_1}$ gibt an, wie stark die Kostenfunktion $C_x$ mit einer Änderung von $w_1$ anwächst. Also erhält man die Richtung des steilsten Abstiegs als negative partielle Ableitung: \begin{eqnarray} w_1^{neu} &:=& w_1^{alt} - \frac{\partial C_x}{\partial w_1} \\ w_2^{neu} &:=& w_2^{alt} - \frac{\partial C_x}{\partial w_2} \\ b^{neu} &:=& b^{alt} - \frac{\partial C_x}{\partial b} \end{eqnarray}Iterationsvorschrift
Daraus erhält man als Iterationsvorschrift zum Updaten der Gewichte $w_1,w_2$ und des Bias' $b$ in jedem Lernschritt: \begin{equation} \boxed{ \begin{array}{rcl} w_1^{neu} &:=& w_1^{alt} + (t-a) \left( 1-a^2 \right) \cdot x_1 \\ w_2^{neu} &:=& w_2^{alt} + (t-a) \left( 1-a^2 \right) \cdot x_2 \\ b^{neu} &:=& b^{alt} + (t-a) \left( 1-a^2 \right) \end{array} } \end{equation}Werden die Gewichte $w_1, w_2$ und der Bias $b$ nach dieser Iterationsvorschrift nacheinander für alle Tiere $x$ abgeändert, so erhält man schrittweise eine Verringerung der Gesamtklostenfunktion $C$, was wiederum bedeutet, dass das künstliche Neuron immer besser lernt, Tiere nach den Kategorien "ungefährlich" bzw. "gefährlich" zu klassifizieren.
Bezeichnung Gradientenabstiegsverfahren
Man bezeichnet den Vektor $$ \nabla_x C_x = \left( \frac{\partial C}{\partial w_1} ,\frac{\partial C}{\partial w_2},\frac{\partial C}{\partial b} \right)^T $$ als so genannten Gradienten der Funktion $C_x$. Der Gradient gibt bei einer mehrdimensionalen Funktion die Richtung des steilsten Anstiegs an. Daher kommt die Bezeichnung des gerade beschriebenen Verfahrens als so genanntes Gradientenabstiegsverfahren.Wer mehr über den Begriff des Gradienten erfahren möchte kann sich die Video über multivariable Calculusvon Grant Sanderson (von 3Blue1Brown) anschauen, die er für die Khan Academdygemacht hat. Achtung: Diese drei Links sind ein ganz schön großes Mathematik-Rabbit-Hole.
Also am besten Bookmarks für die drei Links setzten und diese mal in Ruhe anschauen, denn jetzt geht es hier im nächsten Unterkapitel erst einmal weiter zu einem Jupyter-Notebook mit der Umsetzung des Gradientenabstiegverfahrens in Python.
