Fachkonzept Forward-Propagation
Wir betrachten nun ein allgemeines künstliches neuronales Netzwerk (KNN) mit beliebig vielen hidden Layern und einer beliebigen Anzahl an künstlichen Neuronen in jedem dieser Layer:
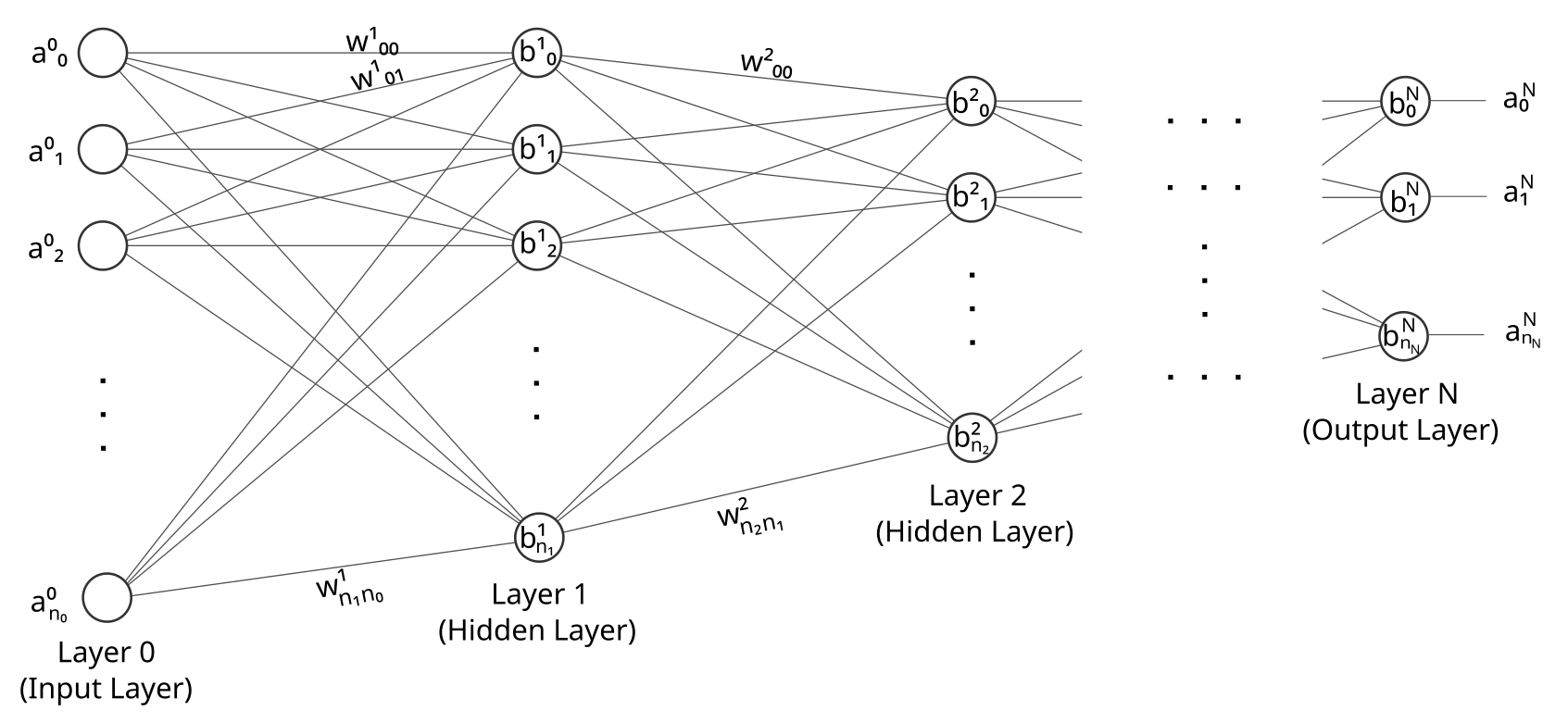
Bei vorgegebenen Gewichten $w_{jk}^l$ und Schwellenwerten $b_j^l$ können aus einen gegebenen Eingangsvektor $\vec{a}^0$ sukzessive die Aktivierungen $\vec{a}^l$ des nächstfolgenden Layers berechnet werden, bis schließlich der letzte Ausgabelayer erreicht ist. Dieses Vorgehen bezeichnet man als Forward-Propagation.
Die sukzessive Forward-Propagation eines Eingangsvektors $\vec{a}^0$ durch das gesamte KNN kann elegant und übersichtlich als Matrix-Vektor-Multiplikation formuliert werden. Um die dazu nötigen Matrizen zu definieren, betrachten wir zunächst zwei einzelne miteinander verknüpfte künstliche Neuronen der aufeinander folgenden Layer des Netzwerks:
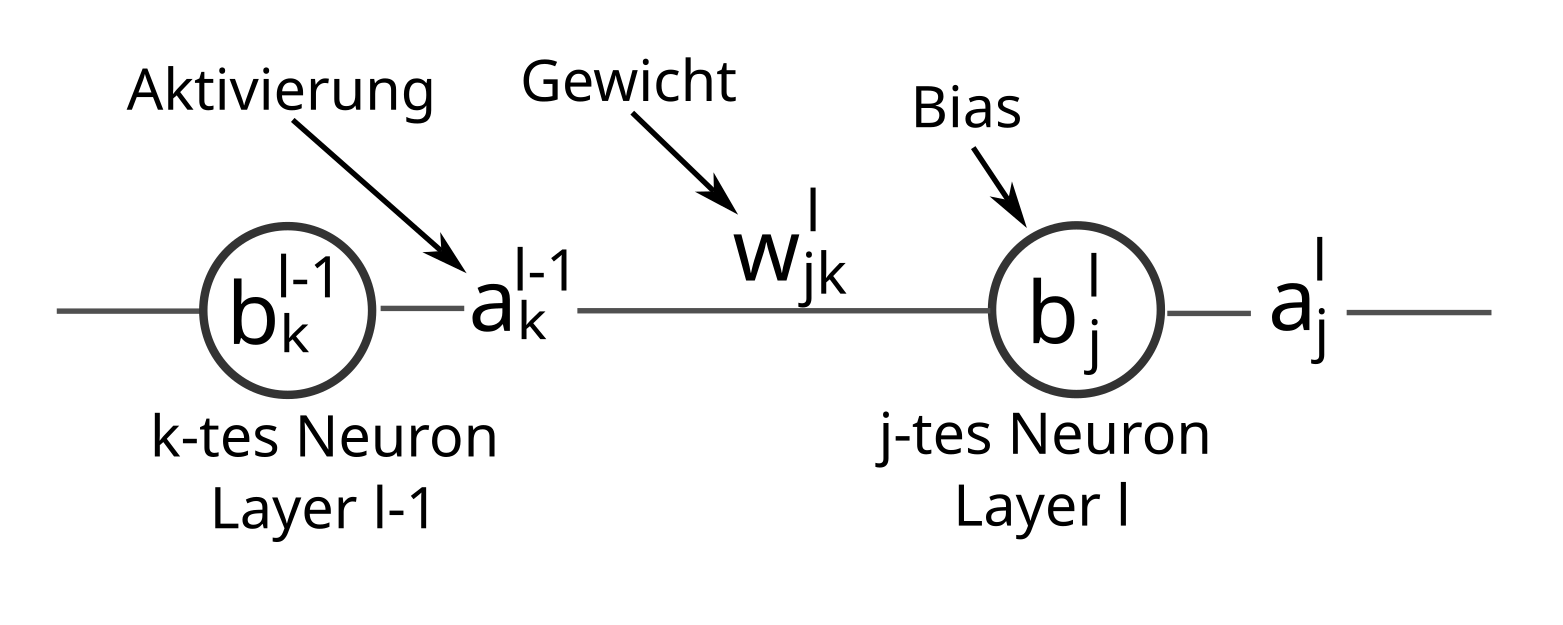
Das linke Neuron ist das $k$-te Neuron des Layers $l-1$, das rechte ist das $j$-te Neuron des darauffolgenden Layers $l$. Mit $w_{jk}^l$ wird das zugehörige Eingangsgewicht des rechten Neurons und mit $a_j^l$ sein Ausgang, also seine Aktivierung bezeichnet.
Damit können wir die Aktivierung des einzelnen rechten Neurons im Layer $l$ als Summe über alle Neuronen im linken Layer $l-1$ schreiben als:
\begin{eqnarray} a_j^l := \sigma \left( \sum_k w_{jk}^l a_k^{l-1} + b_j^{l} \right) \nonumber \end{eqnarray}
Mit den Definitionen \begin{eqnarray} W^l &:=& \left( w_{jk}^l \right)_{jk} \hspace{5mm} \textrm{für die Gewichtsmatrix} \nonumber \\ \vec{b}^l &:=& \left( b_j^l \right)_j \hspace{10mm} \textrm{für den Vektor der Schwellenwerte} \nonumber \\ \vec{a}^l &:=& \left( a_j^l \right)_j \hspace{9,5mm} \textrm{für den Vektor der Ausgangsaktivierungen} \nonumber \end{eqnarray} kann die obige Gleichung in Matrix-Vektor-Schreibweise geschrieben werden als: \begin{eqnarray} \vec{a}^l := \vec{\sigma} \left( W^l \vec{a}^{l-1} + \vec{b}^{l} \right) \nonumber \end{eqnarray} Dabei ist mit $\vec{\sigma}$ die komponentenweise Anwendung der Aktivierungsfunktion gemeint, also $( \vec{\sigma}(\vec{z}))_j := \sigma(z_j)$ für alle $j$.Anmerkung
Die einzelnen Layer können jeweils eine unterschiedliche Anzahl an künstlichen Neuronen enthalten. In der obigen Notation sollen die Indizes $j,k$ jeweils alle Knoten (also Neuronen) des zugehörigen Layers durchlaufen. Auf die Angabe der konkreten unteren und oberen Grenze des jeweiligen Layers wird dabei jedoch verzichtet, um die Notation nicht unnötig zu überladen.
