Gradientenabstiegsverfahren
Sei nun $X$ ein Menge von Trainingsdaten. Das heißt, für jedes $x \in X$ sei die gewünschte Ausgangsaktivierung $y(x)$ eines KNN bekannt.
Weiter sei ein KNN gegeben, welches für Eingangsaktivierungen $a^0 = x \in X$ durch Forwardpropagation Aktivierungen $a^L(x)$ am Ausgang des KNN berechnet.
Sämtliche Gewichte $w = (w_{jk}^l)_{j,k,l}$ und Biases $b=(b_j^l)_{j,l}$ des KNN seinen zunächst einfach mit reellen Zufallszahlen belegt. Das hat natürlich zur Folge, dass das KNN zunächst für jeden Eingangswert $x$ auch nur zufällige Ausgangsaktivierungen $a^L(x)$ liefern wird, welche zunächst also den gewünschten Ausgangsaktivierungen $y(x)$ noch überhaupt nicht entsprechen.
Um ein Maß dafür formulieren zu können, wie stark die Ausgangsaktivierungen $a^L(x)$ von den gewünschten Ergebnissen $y(x)$ abweichen, definieren wir eine so genannte Kostenfunktion $C_x(w,b)$, die von sämtlichen Gewichten $w = (w_{jk}^l)_{j,k,l}$ und Biases $b=(b_j^l)_{j,l}$ des KNN abhängt:
\begin{eqnarray} C_x(w,b) := {1 \over 2} \| y(x) - a^L(x)\|^2 = {1 \over 2} \sum_k ( y(x) - a^L(x) )^2 \nonumber \end{eqnarray}Ziel des Trainings unseres KNN ist nun, die Gewichte $w$ und die Biases $b$ so zu justieren, dass die Kostenfunktion $C_x$ möglichst klein wird. In diesem Fall liegen die berechneten Ergebnisse $a^L(x)$ dann also (im Sinne der Kostenfunktion) nahe an den gewünschten Ergebnissen $y(x)$ und wir sagen, dass KNN wurde trainiert. In dem Fall, dass die Kostenfunktion sogar ganz verschwinden würde, hätte das KNN alle Trainingsdaten sogar perfekt gelernt. Im Weiteren verfolgen wir aber lediglich das Ziel, die Kostenfunktion möglichst weit (aber eben nicht vollständig) zu minimieren, denn in der Praxis wird es im Allgemeinen nicht gelingen, die Kostenfunktion vollständig zum Verschwinden zu bringen. Mit anderen Worten, wir beschränken uns auf die Suche nach lokalen Minima der Kostenfunktion $C_x$, da deren globales Minimum im Allgemeinen numerisch nicht auf einfache Art zugänglich ist.
Unser Ziel ist es nun, partielle Ableitungen der Kostenfunktion nach sämtlichen Variablen $w,b$ zu bilden und diese Variablen dann in jedem Lernschritt so neu zu justieren, dass der Wert der Kostenfunktion dabei jeweils etwas kleiner wird. Man nennt ein solches Verfahren Gradientenabstiegsverfahren. Das heißt, für einen festen Eingangswert $x$ wollen wir das KNN in einer gewissen Anzahl von Schritten nach der folgenden Vorschrift trainieren:
\begin{eqnarray} \Delta w_{jk}^{l,neu} := - \eta { {\partial C_x} \over {w_{jk}^{l}} } (w^{alt},b^{alt}) \nonumber \\ \Delta b_{j}^{l,neu} := - \eta { {\partial C_x} \over {b_{j}^{l}} } (w^{alt},b^{alt}) \nonumber \nonumber \end{eqnarray}Der Parameter $\eta$ regelt die Lerngeschwindigkeit des KNN, wodurch verhindern werden soll, beim Abstieg zu schnell über ein lokales Minimum hinauszulaufen.
Anmerkung: Ein solches Gradientenabstiegsverfahren kann als Verallgemeinerung des Newton-Verfahrens betrachtet werden. Beim Newtonverfahren wird in Richtung der negativen Ableitung einer einzigen Variablen abgestiegen. Beim Gradientenverfahren werden alle Variablen gleichzeitig betrachtet.
Für das Gradientenverfahren ist nun aber noch notwendig, dass $C_x$ sich auch tatsächlich stetig und differenzierbar ändert mit einer Änderungen in den Variablen $w,b$. Kleine Änderungen von $w$ bzw. $b$ sollen also auch nur kleine Änderungen von $C_x$ zur Folge haben. Damit dies der Fall ist, wählen wir als Aktivierungsfunktion weider die glatte so genannte Sigmoidfunktion $\sigma$:
\begin{eqnarray} \sigma(z) := {1 \over {1+e^{-z}}} \nonumber \end{eqnarray}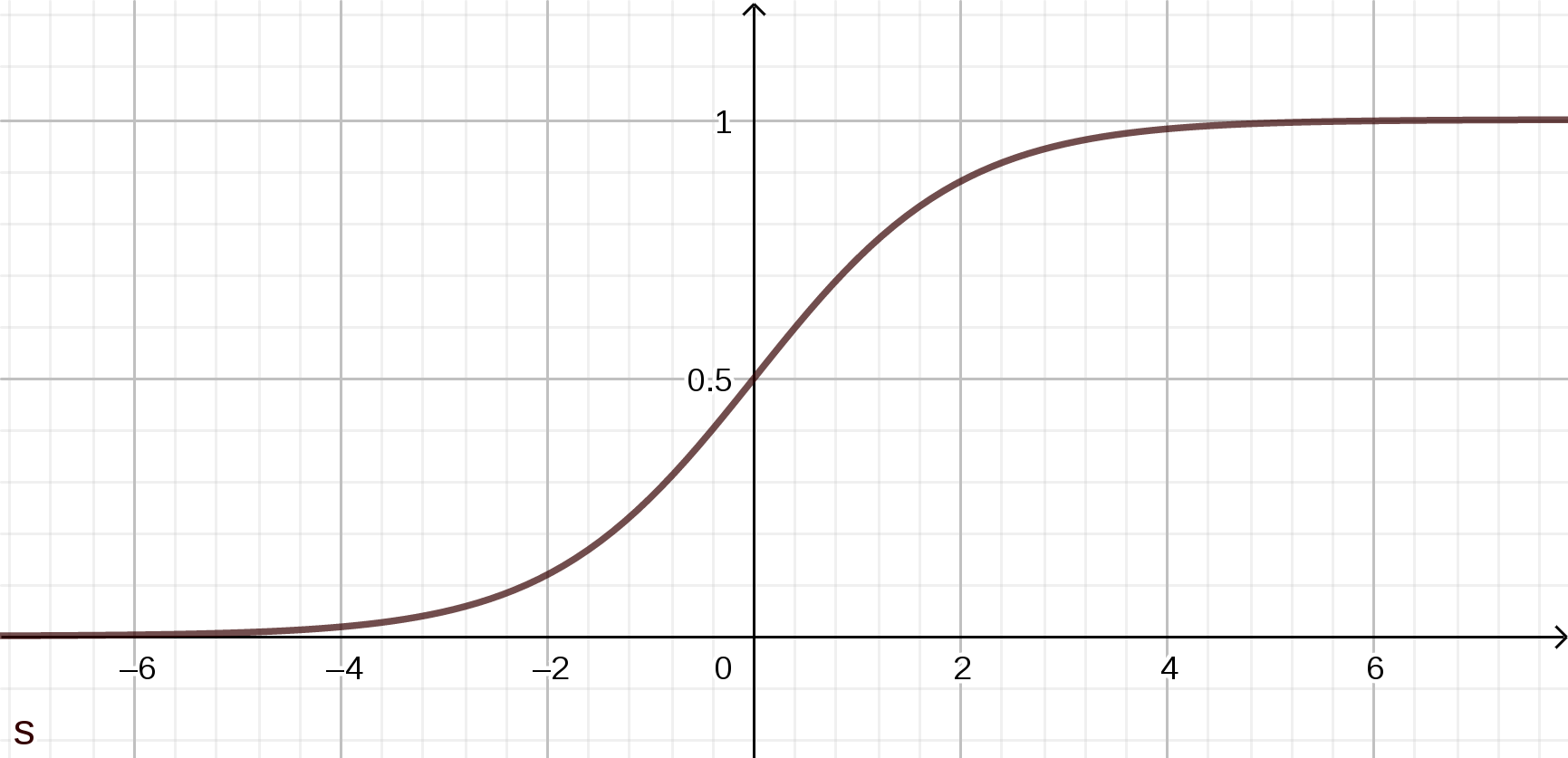
Damit ist die Kostenfunktion $C_x(w,b)$ nun also differenzierbar und wir könnten das oben geschilderte Gradientenverfahren sofort anwenden, indem wir einfach nacheinander jeweils genau eine der Variablen $w_{jk}^l$ bzw. $b_j^l$ betrachten, während wir die anderen Variablen dabei jeweils konstant halten.
Das würde auch funktionieren, allerdings müsste dann in jedem Lernschritt zu einem (festen) Eingangswert $x$ eine Vielzahl einzelner Newton-Iterationen durchgeführt werden, nämlich eine für jeden Gewichtswert $w_{jk}^l$ und eine für jeden Bias $b_j^l$. Da in tatsächlichen Anwendungen die Anzahl an Gewichten $w$ und Biases $b$ aber meist sehr groß ist, wäre dieses Vorgehen numerisch leider nur sehr ineffizient.
Deshalb wird im folgenden Kapitel nun ein Verfahren angegeben, bei dem in jedem Lernschritt für einen festen Eingangswert $x$ alle Gewichte $w$ und alle Biases $b$ gleichzeitig neu justiert werden.
