Erkundung - DOM-Baum
Die "Welt der Oberstufenkurse"
Wir betrachten noch einmal die "Welt der Oberstufenkurse" an einer Schule. Wir lassen hier zur Vereinfachung die Personen, die einen Kurs ausmachen, weg und stellen Kurse in der folgenden Weise mit XML-Dokumenten dar:
<?xml version="1.0" encoding="iso-8859-1"?>
<Kurs>
<Fach>Informatik</Fach>
<Typ>Grundkurs</Typ>
<Stufe>11</Stufe>
<Bezeichner>11-in-1</Bezeichner>
<Unterricht>
<Einheit>
<Tag>Montag</Tag>
<Stunde>7</Stunde>
</Einheit>
<Einheit>
<Tag>Mittwoch</Tag>
<Stunde>3</Stunde>
</Einheit>
<Einheit>
<Tag>Mittwoch</Tag>
<Stunde>4</Stunde>
</Einheit>
</Unterricht>
</Kurs>
Ziel ist es, solche XML-Dokumente automatisiert zu verarbeiten.
XML-Dokument als Baum
Die XML-Elemente-Struktur des oben gezeigten XML-Dokuments lässt sich mit dem folgenden Baumdiagramm verdeutlichen:
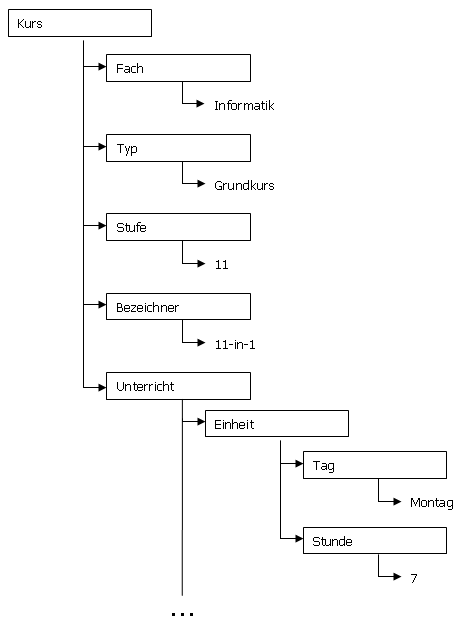
Mit dem Python-Programm DOM-Baum kann man die Baumstruktur eines XML-Dokuments erkunden.
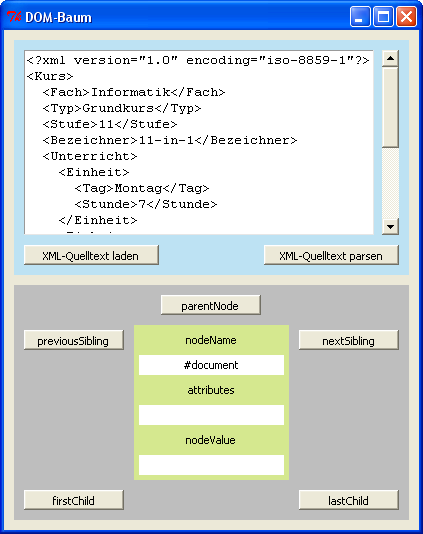
Aufgabe 1
(a) Probiere das selbst einmal aus. Lade zunächst das XML-Dokument Informatikkurs.xml und führe [XML-Quelltext parsen] aus. Versuche, alle Knoten des oben gezeigten Baumes zu besuchen.
(b) Beschreibe anhand der folgenden Abbildung, was die Operationen parentNode, previousSibling, nextSibling,
firstChild und lastChild bewirken.
(c) Der DOM-Baum in der folgenden Abbildung unterscheidet sich geringfügig vom XML-Elemente-Baum oben. Worin bestehen diese Unterschiede?
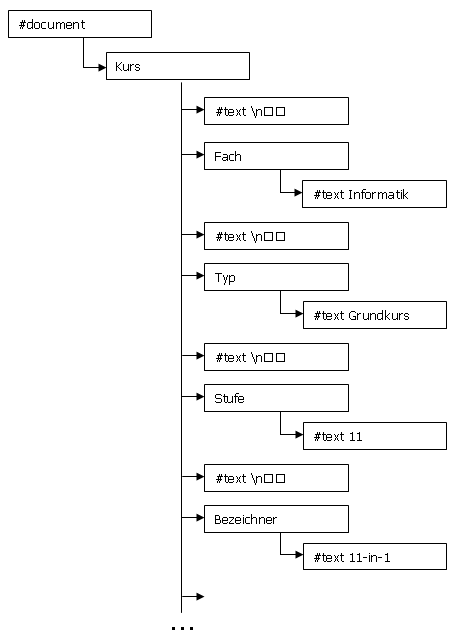
Navigation im DOM-Baum
Das folgende Python-Programm zeigt, wie man aus einem XML-Quelltext einen DOM-Baum erzeugt und wie man mit Hilfe von Operationen im DOM-Baum navigiert.
from xml.dom.minidom import *
# Quelltext in einen DOM-Baum umwandeln
xml_quelltext = """<?xml version="1.0" encoding="iso-8859-1"?>
<Kurs>
<Fach>Informatik</Fach>
<Typ>Grundkurs</Typ>
<Stufe>11</Stufe>
<Bezeichner>11-in-1</Bezeichner>
<Unterricht>
<Einheit>
<Tag>Montag</Tag>
<Stunde>7</Stunde>
</Einheit>
<Einheit>
<Tag>Mittwoch</Tag>
<Stunde>3</Stunde>
</Einheit>
<Einheit>
<Tag>Mittwoch</Tag>
<Stunde>4</Stunde>
</Einheit>
</Unterricht>
</Kurs>"""
document = parseString(xml_quelltext)
# Navigation im DOM-Baum
aktuellerKnoten = document
print(aktuellerKnoten.nodeName)
aktuellerKnoten = aktuellerKnoten.firstChild
print(aktuellerKnoten.nodeName)
aktuellerKnoten = aktuellerKnoten.firstChild
print(aktuellerKnoten.nodeName)
aktuellerKnoten = aktuellerKnoten.nextSibling
print(aktuellerKnoten.nodeName)
aktuellerKnoten = aktuellerKnoten.nextSibling
print(aktuellerKnoten.nodeName)
aktuellerKnoten = aktuellerKnoten.nextSibling
print(aktuellerKnoten.nodeName)
aktuellerKnoten = aktuellerKnoten.nextSibling
print(aktuellerKnoten.nodeName)
aktuellerKnoten = aktuellerKnoten.nextSibling
print(aktuellerKnoten.nodeName)
aktuellerKnoten = aktuellerKnoten.nextSibling
print(aktuellerKnoten.nodeName)
aktuellerKnoten = aktuellerKnoten.nextSibling
print(aktuellerKnoten.nodeName)
aktuellerKnoten = aktuellerKnoten.firstChild
print(aktuellerKnoten.nodeName)
print(aktuellerKnoten.nodeValue)
Aufgabe 2
Teste das Python-Programm. Erkläre anhand der Abbildung oben, wie die Ausgaben hier zustande kommen.
Verarbeitung eines DOM-Baumes
Das folgende Python-Programm zeigt, wie man einen DOM-Baum verarbeitet.
from xml.dom.minidom import *
# Quelltext in einen DOM-Baum umwandeln
xml_quelltext = """<?xml version="1.0" encoding="iso-8859-1"?>
<Kurs>
<Fach>Informatik</Fach>
<Typ>Grundkurs</Typ>
<Stufe>11</Stufe>
<Bezeichner>11-in-1</Bezeichner>
<Unterricht>
<Einheit>
<Tag>Montag</Tag>
<Stunde>7</Stunde>
</Einheit>
<Einheit>
<Tag>Mittwoch</Tag>
<Stunde>3</Stunde>
</Einheit>
<Einheit>
<Tag>Mittwoch</Tag>
<Stunde>4</Stunde>
</Einheit>
</Unterricht>
</Kurs>"""
document = parseString(xml_quelltext)
# Verarbeitung eines DOM-Baumes
def kursbezeichner(doc):
k = doc
k = k.firstChild # Kurs
k = k.firstChild # \..
k = k.nextSibling # Fach
k = k.nextSibling # \..
k = k.nextSibling # Typ
k = k.nextSibling # \..
k = k.nextSibling # Stufe
k = k.nextSibling # \..
k = k.nextSibling # Bezeichner
k = k.firstChild # #text
b = k.nodeValue # '11-in-1'
return b
# Test
print(kursbezeichner(document))
Aufgabe 3
(a) Teste das Python-Programm. Was leistet die Funktion kursbezeichner?
(b) Entwickle und teste analog die Funktionen fach und typ, mit deren
Hilfe aus einem XML-Dokument zur Kursdarstellung das Fach bzw. der Kurstyp ermittelt werden.
Weitere Operationen zur Verarbeitung eines DOM-Baumes
Es ist unpraktisch, den gesamten DOM-Baum Schritt für Schritt abzulaufen, um an bestimmte Daten
heranzukommen. Einfacher geht es, wenn man die Operation
getElementsByTagName benutzt, die eine Liste mit allen Knoten des DOM-Baumes liefert, die den
übergebenen Tag-Namen besitzen.
from xml.dom.minidom import *
# Quelltext in einen DOM-Baum umwandeln
xml_quelltext = """<?xml version="1.0" encoding="iso-8859-1"?>
<Kurs>
<Fach>Informatik</Fach>
<Typ>Grundkurs</Typ>
<Stufe>11</Stufe>
<Bezeichner>11-in-1</Bezeichner>
<Unterricht>
<Einheit>
<Tag>Montag</Tag>
<Stunde>7</Stunde>
</Einheit>
<Einheit>
<Tag>Mittwoch</Tag>
<Stunde>3</Stunde>
</Einheit>
<Einheit>
<Tag>Mittwoch</Tag>
<Stunde>4</Stunde>
</Einheit>
</Unterricht>
</Kurs>"""
document = parseString(xml_quelltext)
# Verarbeitung eines DOM-Baumes
def kursbezeichner(doc):
k = doc
kBezeichner = k.getElementsByTagName("Bezeichner")
b = kBezeichner[0].firstChild.nodeValue
return b
def unterrichtsstunden(doc):
ergebnis = []
k = doc
kEinheit = k.getElementsByTagName("Einheit")
for k in kEinheit:
kTag = k.getElementsByTagName("Tag")
tag = kTag[0].firstChild.nodeValue
kStunde = k.getElementsByTagName("Stunde")
stunde = int(kStunde[0].firstChild.nodeValue)
ergebnis = ergebnis + [(tag, stunde)]
return ergebnis
# Test
print(kursbezeichner(document))
print(unterrichtsstunden(document))
Aufgabe 4
(a) Teste das gezeigte Programm. Ändere hierzu auch die Daten im XML-Dokument ab.
(b) Implementiere analog die Funktionen fach und typ, mit deren
Hilfe aus einem XML-Dokument zur Kursdarstellung das Fach bzw. der Kurstyp ermittelt werden.