Daten sammeln - Variante I
Datensatz I: Datensatz selbst erheben
- Fertigt innerhalb eurer Lerngruppe eine Liste von Filmen an, die möglichst viele von euch gesehen haben.
- Recherchiert für jeden dieser Filme sein Erscheinungsjahr und welchen Genres er zuzuordnen ist.
- Ordnet jedem Film eine eindeutige ID zu.
- Erstellt mit einem Texteditor den Filmdatensatz im .csv-Format. Hier ist ein Beispieldatensatz.
- Fertigt Umfragebögen an, auf denen jeder von euch die gesammelten Filme bewerten kann.
- Führt die Umfrage in eurer Lerngruppe oder einer anderen Versuchsgruppe durch.
- Ordnet jedem Umfrageteilnehmer eine eindeutige ID zu.
- Erstellt mit einem Texteditor den Ratingdatensatz im .csv-Format. Hier ist ein Beispieldatensatz.
- Anmerkung: Ihr könnt gerne ein anderes Bewertungssystem nutzen. Im Folgenden wird das 5-Sterne-Bewertungssystem verwendet, da der Datensatz des Netflix Prize diesen beinhaltete.
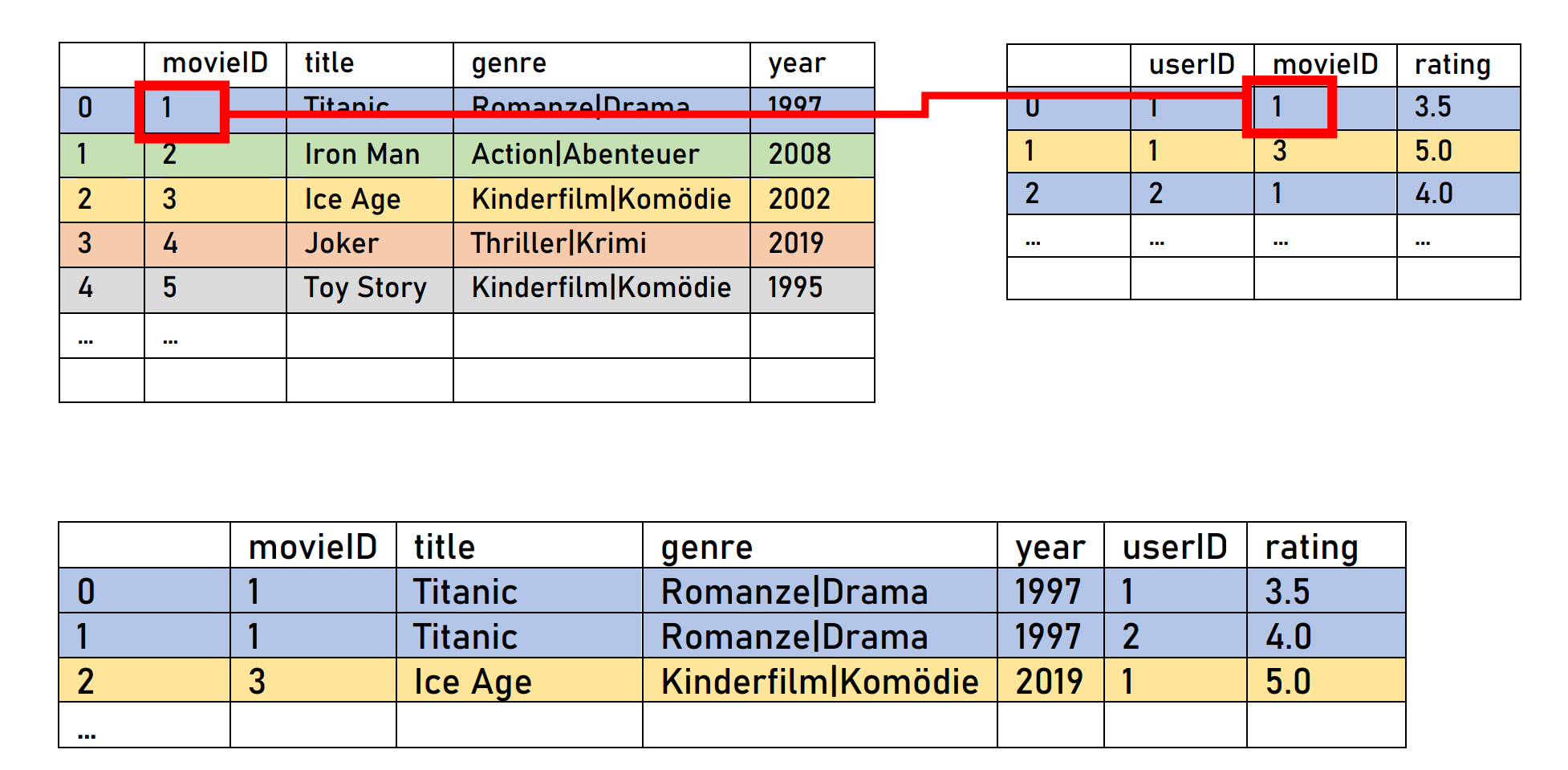
Aufgabe 1 - Informationen in mehreren Datensätzen
Sammle weitere Argumente dafür, warum es sinnvoll ist, zwei seperate Dateien für die Filmdaten und die Bewertungsdaten anzulegen.
Beachte dabei die folgenden Szenarios:
- Ein Nutzer bewertet einen Film.
- Der Name eines Films wird geändert.
- Ein neuer Film kommt hinzu, der noch nicht bewertet wurde.
- Die Regisseure sollen für alle Filme die schon in den Daten sind zusätzlich gespeichert werden.
Andere Möglichkeiten zur Datenerhebung
Wenn wir den Datensatz selbst erheben können wir über dessen Inhalt und Struktur entscheiden. In unserem Fall haben wir eine analoge Umfrage durchgeführt und die Dateien mit den Ergebnissen selbst per Hand erstellt. In der Realität wollen wir jedoch im Allgemeinen deutlich größere Datenmengen, um verlässlichere Informationen ableiten zu können (Link aus Aufgabe aus Bereichsexpertise). Dazu werden Daten digital erhoben, z.B. per Onlineumfrage (im Fall Netflix durch die direkte Eingabe der Bewertung des Films). Das spart sehr viel Zeit und Aufwand. Auch das 'scrapen' von Daten, bei dem wir keine Umfrage anfertigen, sondern schon vorhandene Daten automatisiert aus dem Internet auslesen, liefert uns viele Daten in kurzer Zeit.Ein Beispiel dafür, wie man Daten 'scraped' und was man mit den automatisch ausgelesenen Daten alles machen kann, gibt David Kriesel. Der Data Scientist hat für ein Projekt automatisch Daten von der Deutschen Bahn ausgelesen und diese analysiert.
Aufgabe 2 - Daten scrapen
In seinem Vortrag erklärt David Kriesel, was man beim automatischen Auslesen von Daten beachten sollte. Schaue dir das Video des Votrags von David Kriesel
von Minute 21:10 bis 29:15 an.
- Erstelle eine Liste mit Kriterien, die man beim scrapen von Daten beachten sollte.
- Erkläre für jedes Kriterium am Beispiel der Bahn, warum das Kriterium wichtig ist.